Apache Beam is a distributed data processing framework that allows for easy implementation of data pipelines for batch and streaming data. It provides a unified programming model across multiple languages and data processing frameworks, allowing developers to focus on the business logic of their pipelines rather than the underlying infrastructure.
Google Cloud Workflows is a serverless orchestration service that helps automate and coordinate tasks across different services and systems. It provides a visual workflow designer, making it easy to build, test, and deploy workflows that can handle complex business logic and integrate with other Google Cloud services.
This blog post aims to demonstrate how Google Cloud Workflows can enhance the performance of streaming Apache Beam pipelines. To illustrate this, we will explore the use of this technology in the context of e-commerce order and shipping analytics.
Data analytics has become an essential component of e-commerce due to the vast amount of data generated through online transactions. With the increasing competition in the e-commerce industry, businesses need to leverage this data to understand customer behaviour, improve their offerings, and optimize their operations. By using data analytics, businesses can gain insights into customer preferences, identify trends, optimize pricing and promotions, improve supply chain efficiency, and enhance the overall customer experience. E-commerce companies that do not take advantage of data analytics risk falling behind their competitors and losing out on potential revenue opportunities.
By using Apache Beam and Google Cloud Dataflow, e-commerce companies can analyze their order and shipping data in real-time, providing valuable insights into customer behaviour and supply chain operations. For example, they can track inventory levels, predict demand, optimize shipping routes, and detect fraudulent orders.
In addition to real-time analytics, Apache Beam and Dataflow also enable batch processing, which can be used to analyze historical data and identify trends and patterns. This can help e-commerce companies make better business decisions and improve customer satisfaction.
Overall, Apache Beam and Google Cloud Dataflow are powerful tools that can help e-commerce companies gain valuable insights from their order and shipping data. By leveraging these tools, companies can improve their operations, reduce costs, and ultimately drive revenue growth.
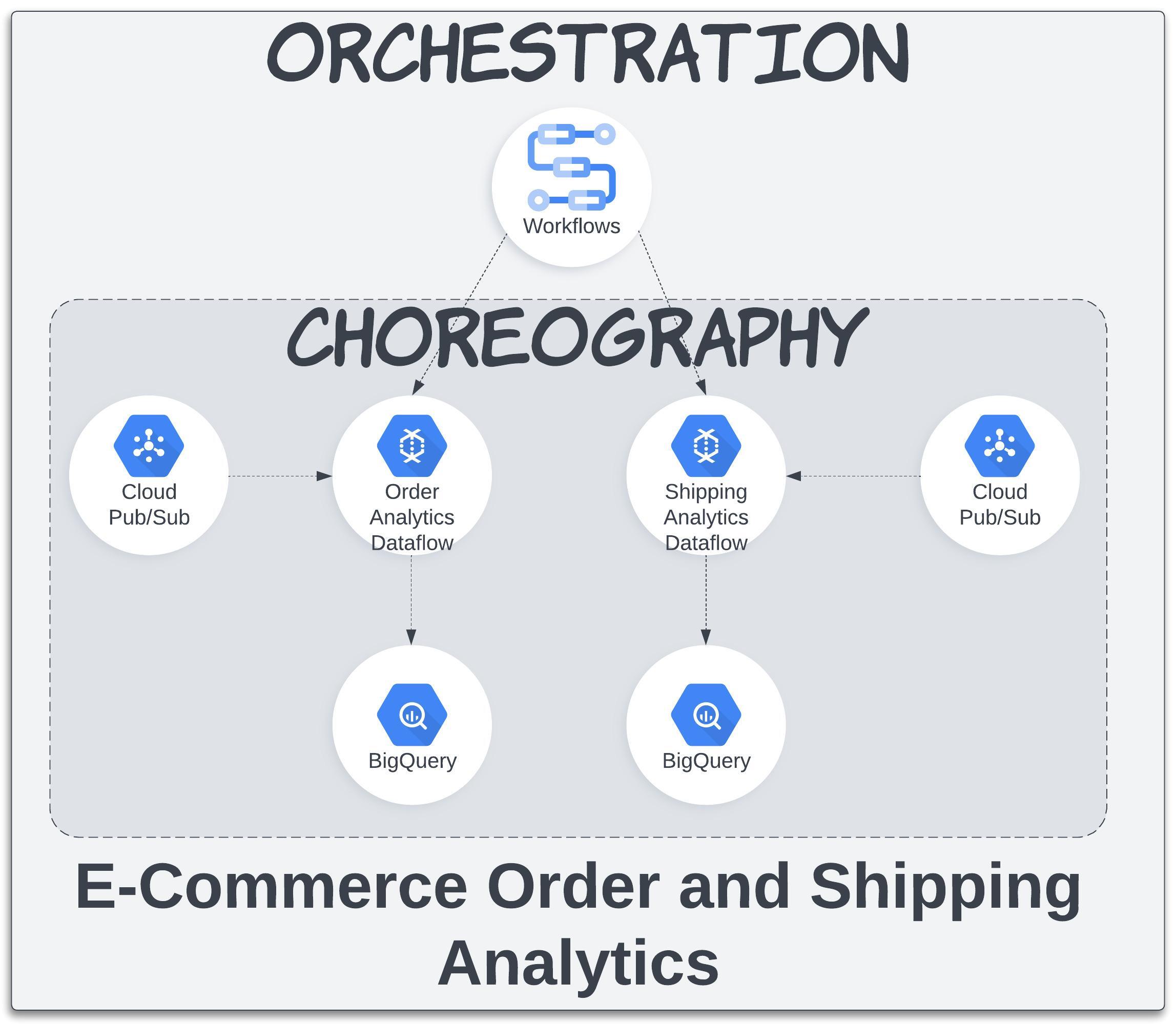
A simplified order and shipping analytics process can be described in the below format:
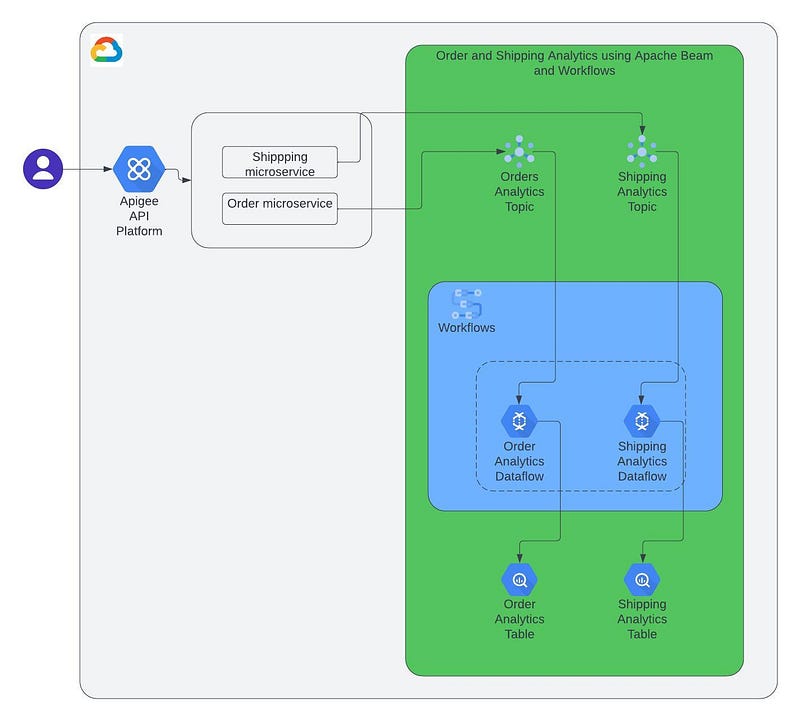
- The order and shipping details are published on respective topics.
- The topics are subscribed by the streaming pipelines.
- After performing the necessary data preprocessing and transformations, the data can then be written to BigQuery tables.
- By leveraging GCP Workflows, we can effectively orchestrate the streaming pipelines and ensure their uptime, making them suitable for real-time analytics.
Following insights can be generated in realtime while analyzing the order and shipping data in realtime.
- Sales trends: By analyzing the sales data over time, businesses can identify patterns and trends in customer behavior, which can help with forecasting, inventory management, and marketing strategies.
- Product performance: Analyzing sales data can also help businesses understand which products are selling well and which are not, allowing them to optimize their product offerings and marketing strategies.
- Customer segmentation: By analyzing customer data, businesses can segment their customers based on demographics, purchasing behavior, and other criteria, allowing them to create targeted marketing campaigns and improve the customer experience.
- Order fulfillment efficiency: Analyzing shipping data can help businesses identify inefficiencies in their order fulfillment processes, such as delays or errors, and take steps to improve them.
- Supply chain optimization: By analyzing shipping data, businesses can identify patterns in their supply chain, such as bottlenecks or delays, and take steps to optimize it for efficiency.
- Fraud detection: By analyzing order data, businesses can identify patterns of fraudulent activity, such as fake orders or stolen credit card information, and take steps to prevent it.
Let’s now delve into the technical aspects of this solution.
To begin with, we can set up two streaming Dataflow jobs: one for order and the other for shipping. For the sake of simplicity, both jobs can be configured to read data from a Pub/Sub topic and write it to a BigQuery table. However, in reality, the logic of these Dataflow jobs can be much more complex and may involve multiple data cleaning, preprocessing, and transformation steps.
Streaming Dataflows can be seen as an implementation of the choreography design pattern, as they directly interact with the input and output sources of data.
Following are the GitHub links to the apache beam pipelines that you can use as reference.
https://github.com/mkhajuriwala/orderAnalyticsBeamPipeline
https://github.com/mkhajuriwala/orderAnalyticsBeamPipeline
After you have written your Apache Beam code, you can generate a flex template using the commands provided in the readme file.
Note: Make sure you have enabled Dataflow, Compute Engine, Logging, Resource Manager, App Engine, Artifact Registry APIs.
Now lets look at the GCP workflow configuration:

The main workflow consists of two parallel branches. One branch calls the sub-workflow to orchestrate the order pipeline and another one for shipping pipeline.
Note: The parallel branches continue execution irrespective of any exception that occurs in the other branch. If all the branches throw an exception then the workflow fails.
Since both branches contain the same logic, let me provide an explanation for one of them.

The order/shipping branch involve the following steps
- The first step creates a dataflow job using the flex template stored in cloud storage.
- The second step is to iteratively check the status of the job to ensure that its working fine.
- The remaining steps involve either setting up the job to be retried a finite number of times in the event of failure or terminating the process once the maximum number of retries has been reached.
Launch Dataflow Job Step
This step again is a sub-workflow which contains logic regarding creating the dataflow job using google API.

https://github.com/mkhajuriwala/orderAnalyticsBeamPipeline
Above webpage is a good starting point to understand the requirements to create a dataflow job. But in a nutshell, the following details are required.
- Flex or classic template
- Required parameters, such as job name, project ID, job parameters, and pipeline options.
- Configuration settings for the Dataflow job, such as machine type, disk size, and network settings.
The Job Id returned as part of the response is used to monitor the status of the job.
Pipeline status check step

This step involves monitoring the ongoing execution of Dataflow jobs. After the job has been created in the previous step, its ID is used to retrieve job details via the Dataflow get API, which is called every 30 seconds to check that the job status is not in one of the terminal states (i.e., [“JOB_STATE_FAILED”, “JOB_STATE_CANCELLED”, “JOB_STATE_UPDATED”, “JOB_STATE_DRAINED”]).
If the status changes to any one of the above then the workflow goes to the “Launch Dataflow Job Step” to create a new dataflow job.
By following this approach, the workflow can effectively orchestrate Dataflow jobs and recreate failed jobs a finite or infinite number of times based on the specified retry conditions. In the present case, the workflow will recreate a job only twice if the previous job has terminated. However, this number can be adjusted as per the requirements of the use case.
Workflows as an orchestration layer can do various tasks such as
- Pipeline scheduling: Schedule the execution of the pipelines based on the availability of data and resources, and can ensure that the pipelines are executed in the correct order.
- Data routing: It can route data between pipelines, ensuring that the data is properly passed from one pipeline to the next.
- Pipeline monitoring: Monitor the execution of the pipelines, and can detect and resolve issues in real-time, such as pipeline failures or slowdowns.
- Resource management: Manage the allocation of resources, such as compute, storage, and network resources, to ensure that the pipelines have the resources they need to execute effectively.
Thats it, by combining orchestration and choreography, you can create a hybrid design that is flexible enough to address a range of use cases, including real-time data processing, ETL processes, IoT data processing, and log processing.
You can refer to the workflow at the below GitHub location.
https://github.com/mkhajuriwala/orderAndShippingGCPWorkflow
In order to run the workflow you can take the code and update the input params in the readme section.
https://gist.github.com/mkhajuriwala/971d1a12d8896f2c3c0a1d3a2cfbf7a4
Also make sure that the service account you use has the right permissions required by the dataflow to do its job
The pricing for GCP Workflows is based on the number of steps executed, and since we’re not accessing any external APIs in this workflow, all the steps are internal. With 5000 free internal steps and a charge of $0.01 per increment of 1,000 steps after that, orchestrating two streaming Dataflow pipelines with no retry limit would cost approximately $17 to $18 per month.